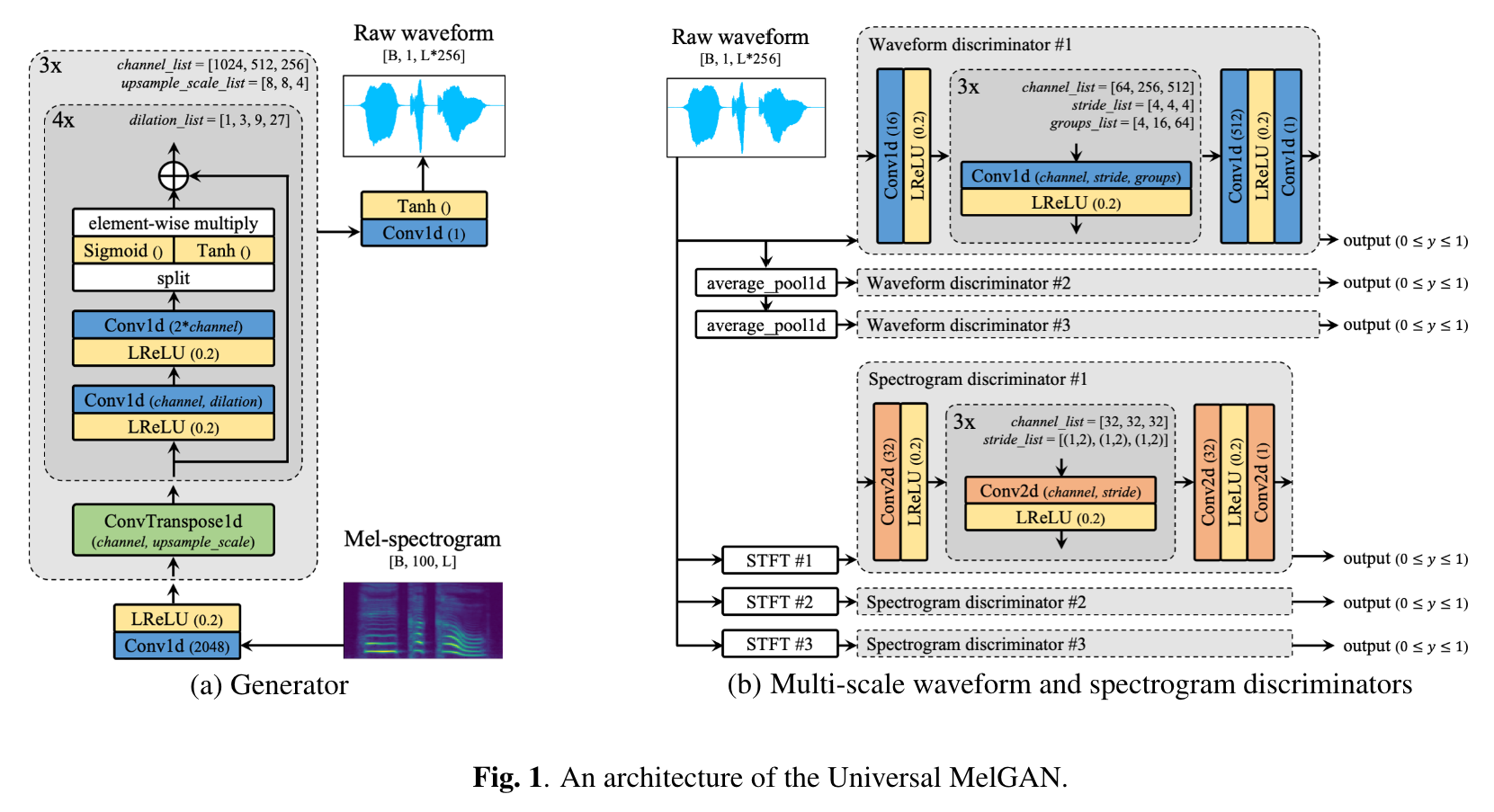
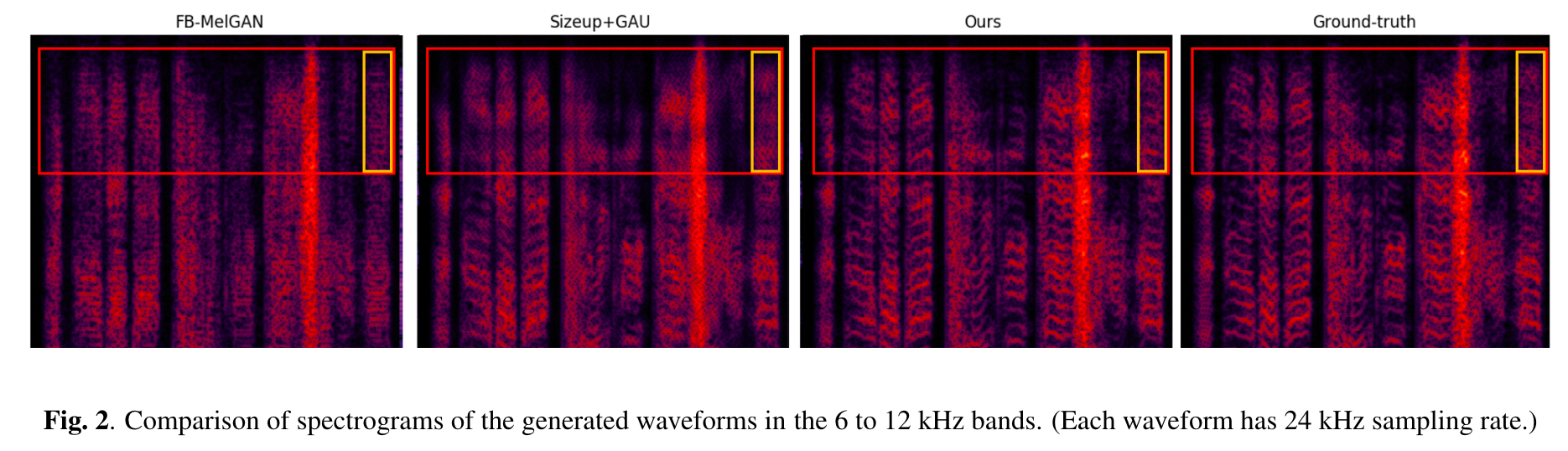
We propose Universal MelGAN, a vocoder that synthesizes high-fidelity speech in multiple domains. To preserve sound quality when the MelGAN-based structure is trained with a dataset of hundreds of speakers, we added multi-resolution spectrogram discriminators to sharpen the spectral resolution of the generated waveforms. This enables the model to generate realistic waveforms of multi-speakers, by alleviating the over-smoothing problem in the high frequency band of the large footprint model. Our structure generates signals close to ground-truth data without reducing the inference speed, by discriminating the waveform and spectrogram during training. The model achieved the best mean opinion score (MOS) in most scenarios using ground-truth mel-spectrogram as an input. Especially, it showed superior performance in unseen domains with regard of speaker, emotion, and language. Moreover, in a multi-speaker text-to-speech scenario using mel-spectrogram generated by a transformer model, it synthesized high-fidelity speech of 4.22 MOS. These results, achieved without external domain information, highlight the potential of the proposed model as a universal vocoder.
Korean samples
For Korean, each model was trained on studio-quality internal datasets with 62 speakers and 265k utterances.
‘Seen’ indicates that the domain has been trained.
‘Unseen’ indicates that the domain has never been trained.
Seen speakers
Single speaker
Index
Recording
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
#1
#2
#3
Multiple speakers
Index
Recording
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
#1
#2
#3
Unseen domains: speaker, emotion, language
Unseen speakers
Index
Recording
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
#1
#2
Expressive utterances
Index
Recording
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
Sportscasting
Anger
Disgust
Fear
Happiness
Sadness
Unseen languages
Index
Recording
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
Spanish
German
French
Japanese
Chinese
Multi-speaker text-to-speech
To evaluate this scenario, we trained the JDI-T acoustic model with a pitch and energy predictor using a dataset with four speakers.
Each trained vocoder was fine-tuned by 100k steps using a pair of the ground-truth waveforms and the predicted mel-spectrograms.
Note that we prepared the predicted mel-spectrograms of JDI-T by using the text, reference duration, ground-truth pitch, and energy.
Index
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
#1
#2
#3
#4
English samples
For English, each model was trained on LJSpeech and LibriTTS datasets with 905 speakers and 129k utterances.
‘Seen’ indicates that the domain has been trained.
‘Unseen’ indicates that the domain has never been trained.
Seen speakers
Single speaker
Index
Recording
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
#1
#2
#3
Multiple speakers
Index
Recording
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
#1
#2
#3
Unseen domains: speaker, emotion, language
Unseen speakers
Index
Recording
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
#1
#2
Expressive utterances
Index
Recording
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
#1
#2
#3
#4
#5
#6
Unseen languages
Index
Recording
Universal MelGAN
FB-MelGAN
WaveRNN
WaveGlow
Spanish
German
French
Japanese
Chinese
Text-to-speech
We trained the single-speaker Tacotron 2 acoustic model with the LJSpeech dataset.
LJSpeech
Index
Universal MelGAN
#1
#2
#3
Additional study
Korean TTS samples: Predicted mel-spectrogram of unseen speakers
Trained but not fine-tuned speakers
Index
Universal MelGAN
#1
#2
#3
Not trained and not fine-tuned speakers
Index
Universal MelGAN
#1
#2
Korean TTS samples: Multi-band + mixed precision
This study achieved 0.003 RTF on an NVIDIA V100 GPU.